
I was inspired by attending Angus Lees’ [garage Kubernetes](https://archive.org/details/lca2018-How_to_run_Kubernetes_on_your_spare_hardware_at_home_and_save_the_world talk) at linux.conf.au 2018; not in the direct way of setting up Kube at home (although that’s on my to-do list); rather, to solve what Angus mentioned in passing as the biggest pain point for lab/SOHO environments: storage. Storage is still a SPOF1 for most SOHO-type environments.
There’s a good reason for that: distributed systems are hard. Distributed storage is the hardest part of that problem. But it’s also the most worthwhile problem to solve; if you can have reliable distributed storage, you’ll never wake up to find a note from your 5 year old bemoaning that she can’t watch TV again.
What we’re trying to achieve: User Stories
SOHO User:
- I don’t want to have outages.
- I want Kodi to work.
- I want my files always there.
- I don’t want to have to wait for someone to come fix things because of a minor problem.
Admin:
- I don’t want to be stuck with something important not working when the stores are closed and I don’t have spare parts.
- I don’t want to get a call when I’m overseas saying everything is broken and try to talk someone at home through buying a new motherboard and replacing the old one.
- I don’t want to spend all my time running this system. It needs to (mostly) look after itself.
- I want to be able to make changes, do upgrades, and so on, when I feel like, not when no-one else is using the system at 2 in the morning.
- It’s needs to be easy to fix when something fails or when I (inevitably) fuck something up2.
- I don’t want to have to spend a fortune adding new drives to a single server.
Just to elaborate on that last point: 6 ports of storage in a server? Cheap! 8-10? Not too bad. Prices - for cases, power supplies, and controllers - all start to hockey stick after that point, though. You can easily pay half as much again for the port (adding up the cost of the case slots, the ports, and the power supplies) as for a cheap drive.
Either way, nirvana looks like:
- Component failures shouldn’t be visible to end-users. Things should Just Work.
- Component changes shouldn’t be visisble to end-users.
- Changes and repairs should be easy - conceptually easy to understand, and technically easy to perform.
- It should be cheap - the kind of thing you can pair with a couple of cobbled-together servers.
Why Gluster?
Gluster is certainly not the sexiest of the distributed storage options. That would be Ceph - the superstar of this part of the tech landscape. There’s good reason for the, too: Ceph is based on some really smart thinking; it scales more or less indefinitely - you’re more likely to flood a 100 Gbps datacentre switch than to run out of scale-out/up in Ceph; it’s incredibly resilient. The thing is, though, that there are some drawbacks to Ceph: the most obvious is that while Ceph scales up wonderfully well, it doesn’t really scale down so well. The effective minimum for a Ceph cluster is three nodes, and realistically that’s considered a very dense, hyper-converged setup; in practise you probably should be running 5 nodes (for a mix of storage and management). And those nodes should be pretty beefy - it would be foolish to try cramming Ceph into nodes with a few GB of memory. Moreover, it’s fairly complicated, both conceptually and in practise; as Sage noted this year the Ceph team are working hard on making Ceph easier to manage but it’s fundamentally a sophisticated system for solving a hard problem at scale.
None of this means that Ceph is bad. Not at all. Ceph is brilliant, but it’s brilliant for the right use case, which is (probably) not your SOHO build. Which leads me to Gluster:
- It works. It’s been around for a long time.
- It has an active upstream, and a lot of commercial use. It’s not going to be abandonware any time soon, and keeps getting improvements.
- It’s easy to set up and administer.
- This is really, really important in SOHO scenarios.
- Replacing “Talking someone at home through replacing a motherboard” with “talking someone at home through rebuilding a broken Ceph cluster” is not really an improvement.
- It’s cheap. The entry requirements to build a minimally-useful Gluster system are low: gig ethernet, a few gigs of RAM, and a couple of disks and you’re done.
Per that last point: Gluster does scale up, albeit not as well as Ceph, but it scales down, which is what matters for this scenario. To give you an idea of how committed the Gluster team are to scale-down, they’ve just pushed the 4.0 release out the door, using an integrated etcd to provide configuration management. They’re working on 2-node mode for etcd for the set of Gluster users who don’t want to go to running three nodes!
Gluster still provides the resilience we’re after: you can have a two node cluster where node failures simply won’t affect user experience at all. Upgrade, reboot, drop a node to install hardware, or in one case, because the motherboard has failed and you’re buying a new one tomorrow, it makes no difference. But it does it at a much lower cost of entry, and, as I’ll discuss, it has almost all the features we could want for a storage tier. That said, let’s acknowledge some drawbacks up-front:
- Documentation is uneven. The best documentation for Gluster is behind the Red Hat paywall.
- This is not helped by search engines pointing at the many-year-old 3.7 doco as the first entry because Google is now an AltaVista quality search engine.
- This also means many past weaknesses in Gluster are still talked about even when they’ve been resolved.
- Many small files and other high-IOP workloads are a long-standing achilles heel for Gluster. As of newer versions, particularly 3.10 and 3.12 this has been improved considerably.
A Little Bit of Theory
The unit of storage Gluster exposes is the volume; you build a Gluster volume from one or more bricks. Bricks can then reside on one or more hosts. As shown below, a basic setup would see two bricks, on two different hosts, with data replicated between them - network RAID1, if you like.
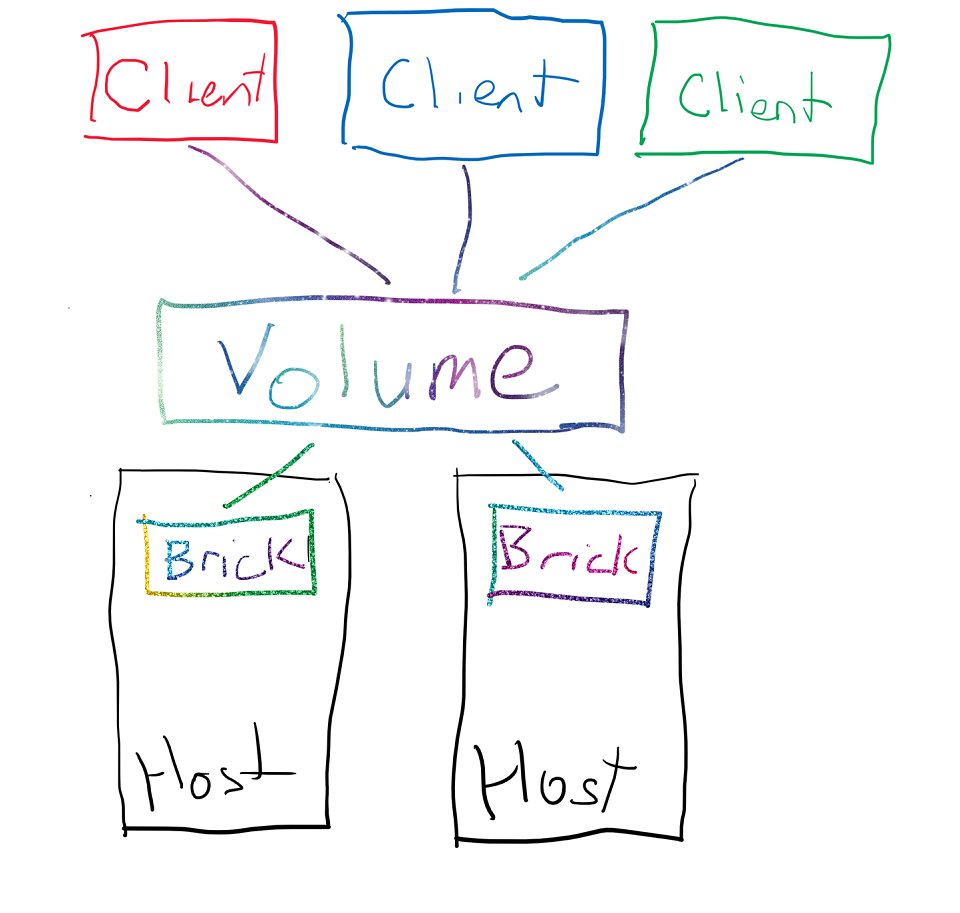
Although the diagram shows the clients connecting to a volume, this is a bit misleading; the clients fetch a map of the volume (from a Gluster volume server) which contains the details of the volume: how many bricks there are, where they’re located on the network and so on. The client driver then speaks directly to the hosts to make sure data is written.
Probably the most important thing to understand about Gluster is that the basic units of storage under the hood are files, rather than objects or file fragments. This underpins pretty much all the benefits and drawbacks of Gluster as a storage server:
- The underlying storage units - bricks - are regular filesystems on standard block devices.
- The choice of filesystem is up to you. You could even mix and match filesystems on different bricks to match the types of files.
- “Extras” like at-rest encryption can be delivered by well-tested components like dm-crypt.
- Disadvantages:
- Doesn’t scale as well as e.g. Ceph.
- Performance will be heavily affected by the size of files and how that maps onto the performance of the underlying disks.
- Advantages:
- Simple model to understand and manage. Don’t under-estimate the value of simplicity, especially in SOHO scenarios.
- Since bricks are filesystems you can, in a worst case scenario where, simply copy files off bricks and rebuild a cluster. It’s very hard to hose a Gluster environment so badly you can’t recover your data.
Gluster metadata is implemented via a combination of extended attributes, SQLite, and hardlinks.
- This can require tuning on the filesystem to support properly, e.g. XFS needs larger-than-normal inodes to work properly with gluster.
- As with files themselves this makes it (relatively) easy to understand and reconstruct what’s going on.
- It comes at a cost, though: performance will be heavily affected by the ratio of metadata operations to file size.
- Many metadata ops across large numbers of files can be utterly abysmal.
rsyncacross lots of small files will make you cry. - There are significant improvements in newer versions of gluster, but they’re tunables which are not on by default. We’ll talk about this later.
- Many metadata ops across large numbers of files can be utterly abysmal.
Initial Setup
Enough theory! How do we make this work?
Preparing Your Hosts
My preference for hosts is Fedora, or CentOS if you don’t want to upgrade your underlying OS. Bear in mind that upstream Gluster is a predominantly Red Hat supported project, so you’re likely to get best support running a Red Hat-related distro. That said, you can run Gluster on many distros; some considerations though3:
- Gluster can run, and run well (by which I mean flood 1 Gbps links) with old/minimal hardware. I’ve used it with Core2Duo and Athlon II processors, with 4GB of RAM installed. You could probably get by with less. Given how old/cheap this kind of kit is, I wouldn’t bother.
- CPU use is a function of the features you enable.
- Memory use is a function of the number of volumes as well as the features enabled, especially if you use some of the newer performance enhancements.
- You can use HDDs or SSDs or whatever. I’m using mostly bulk storage, so spinning rust is where it’s at for me (but see later on for notes on tiering).
- You don’t need fancy controllers, RAID, or what have you.
- I would strongly recommend seperating your drives you use for system disks and bricks.
- Don’t bother RAIDing your system disk. Why waste drive ports and slots when you’ve got a whole other server to cope with a system disk failure?
- Gig ethernet is the practical minimum for Gluster to be useful.
- If you want to make it easy to add clustered Samba later you probably want multiple NICs, but you don’t need them.
- DO NOT USE OLD VERSIONS OF GLUSTER.
- DO. NOT. USE. OLD. VERSIONS. OF. GLUSTER.
Was that clear enough? You really, really want a new, long-term version of Gluster. I use 3.12, and I wouldn’t use less that 3.10. Gluster is under active, heavy development, and a huge number of options, especially performance options, are only available in newer versions. Fedora 27 ships with Gluster 3.12; Fedora 26 falls back to 3.10.
Do not use Gluster 4.0. It isn’t a long-term release, and the gluster2 features are all effectively in preview. Wait for things to settle if you care about your data and sanity.
Preparing Your Bricks
Bricks are the underlying storage for your volumes; the number you need and the layout will depend on how much resilience you want, and the configuration will depend on which trade-offs of performance and complexity matter to you. That said, I have Opinions about the right and wrong way to do this.
Let’s start with RAID. Some people create bricks by RAIDing multiuple disks. I don’t and I don’t recommend it; fundamentally, it’s a waste. Your Gluster setup will replicate data between hosts, giving you multiple copies. If you end up with multiple pairs of bricks in a volume, Gluster will spread files around them for performance benefits. RAID adds overhead, it adds cost, and it adds complexity, and the benefits are minimal, add best. It also makes the environment less resilient and causes failure recovery to take longer (we’ll talk about the details of that later).
Don’t RAID your bricks.
LVM is another consideration. LVM is an increase in complexity, true, but Gluster can take advantage of having an underlying LVM: it can then expose snapshot functionality that makes use of the underlying LVMs. I’m not going to cover off the details of this, because it’s not what I personally use; I’ve been burned by LVM snapshots and thin provisioning in so many ways I’m pretty gun-shy of them. That said, I wouldn’t categorically say “don’t do that”. Just that I haven’t.
At-rest encryption - if you want to have a volume’s data encrypted on-disk, you need to encrypt the bricks. Because the bricks are simply filesystems, you can use dm-crypt (for example) as you would for any filesystem.
From there, choose your filesystem; I prefer XFS, but you can just as easily use ext4 or ZFS or, if you like throwing your data away, btrfs. Note that if you, too, like XFS, you’ll need to use -i size=512 when you build the filesystem in order to give Gluster enough room to store metadata. Then you mount it, and away you go. I prefer to mount under /srv/brickname, with the brick number incorporated in the label and mount point (it makes it easier to keep track of which disk maps to which volume).
Having said all that, don’t sweat it. The beauty of Gluster is that it’s really easy to change your mind. You can (and I have) built with LVM and RAID and then decide that was a stupid idea and rebuild the bricks without, one host at a time, without causing any interruption to your users, replacing the old bricks with new bricks, changing mountpoints… anything really.
Building the Cluster
First you’ll need to make sure you’ve installed the Gluster server software each on your two hosts; in Fedora this is dnf install glusterfs-server. You’ll want to make sure it starts on boot - systemctl enable glusterd - and start it with systemctl start glusterd. Our friend firewalld will be a pain in the arse here; you can either add exceptions for the gluster ports, or disable firewalld, whichever you prefer.
Once you’ve done thig building a Gluster cluster is a matter of logging into one host - let’s call it gluster01 - and pinging another host with gluster peer probe gluster02.
Assuming it works - and you’ve got your firewall ports opened or just switched off - you’ve now got a cluster. Congratulations.
(If you’re thinking, “that can’t be right, clusters are hard”, well, that’s why I recommend Gluster. It’s not difficult.)
Creating a volume
Now you need to assemble your bricks into a volume. For the use case I’ve described - mirroring data across two hosts - we want our volume to be:
- Configured as a replica. Replica volumes have a number of copies of data; we’ll go with two.
- This gets us a warning about split brains. This is a risk, but for a simple network in a SOHO environment, it’s a relatively low risk compared to the performance and cost hit from a three-way mirror.
- We don’t use distributed or any of the more exotic options, all of which dramatically increase cost and/or complexity for no real benefit at this scale.
Note that it’s very ill-advised to create a volume on the top level directory of a mount point. So we want to go to the mountpoint of each brick and create a directory - if your mountpoint is (say) /srv/data-01/ create a directory so you’re adding bricks as below:
gluster volume create data replica 2 gluster01:/srv/data-01/root gluster02:/srv/data-02/root
This will get you a split brain warning. Confirm you want to continue, and then:
gluster volume start data
That’s it. You can test it from a client with:
mount -t glusterfs gluster01:/data /mnt/data
You should see your volume. df will show you the size of the brick and so on.
It’s literally that easy. I have had some pain with the earlier 3.12.x versions of Gluster that shipped with Fedora 27, where the start would fail unless I restarted the gluster daemon (with systemctl restart glusterd) on the codes, then restarted the volume (with gluster volume stop data force and then gluster volume start data).
This is good, but there’s two more things I’d recommend doing before declaring Gluster useful: bitrot protection and quotas.
Bitrot Protection
Gluster can give you bitrot protection, just like all those modern filesystems you’ve heard about. It’s trivial to implement; simply typing gluster volume bitrot data enable on either of your Gluster nodes will do the job. Gluster will now calculate signatures for all files as they’re written and scrub the volumes looking for errors on the bricks from time to time; you can tune how often the bitrot scrub happens.
There are a few caveats: this happens at a file level, not a block level, so whole files will be re-synced if one goes bad; and generating the checksum happens as they’re written. It’s not retrospective, it will not apply to files already on a volume. This is why I recommend you enable it as your first step.
It also adds overhead, of course: every file written now logs extra metadata to the hosts.
Quotas
Gluster has a very sound quota system with soft and hard limits. Unlike some filesystems, the free space as dictated by the quota is accurately reported in df, so that’s extra nice. Enabling and setting quotas is pretty simple:
gluster volume quota data enable
gluster volume quota data limit-usage / 100GB
The soft limit will warn in the logs as it’s approached; the hard limit will ENOSPC when attempting to exceed it. Using quotas it’s very possible to get a single namespace with fine-grained control over who can write to what under the covers.
What Now?
You can start using things straight away. In future posts I’ll look at security (this build is wide open to your network), performance (you’ll want to apply some of the modern options for small file performance at a minimum), as well as making more optimal use (like samba clustering, native samba and libvirt gluster integration, for example) of the cluster, and how to grow your volumes, how to recover from errors (whether of the hardware or fat-finger variety).
-
Single point of failure. The thing that will bring your plans down in a screaming heap. ↩︎
-
Things fail because you fuck with them. Hard drives will run for 3-5 years, even longer. Fat-fingering a server will bring it down more often than hardware failures ever will. ↩︎
-
Note that these recommendations are for a SOHO Gluster setup. If you’re doing Gluster to create a high-end storage system, they’d look completely different. ↩︎